BFF - Emergent Complexity experiment
Self-replicating programs emerge from pure random noise with no fitness function. This is an attempt at replicating the experiment and the results raise questions about the nature of intelligence itself.
What if intelligence isn’t something that needs to be designed, trained, or evolved? What if it is part of the underlaying fabric of the universe and we can make it appear, seemingly from noise, if we give it the right environment?
In June 2024, Google researcher Blaise Agüera y Arcas published a paper called Computational Life that demonstrated something unsettling: take a population of tiny programs filled with random bytes, let them interact with each other, and self-replicating programs emerge spontaneously. No fitness function. No selection pressure. No designer. Just random noise bumping into random noise until, suddenly, something alive shows up.
I wanted to try if I could get this to work myself. Note that this is not a perfect replica of the results Blaise did but an attempt to explore the idea and see if we could get something similar to happen. The answer is: Yes. We do see the same type of self-replicating behavior, just not with as sharp or obvious cut-off point as Blaise shows in his research. Still, the code is on GitHub (linked at the end). Feel free to give it a go yourself and see what results you get.
The Experiment
The setup is deceptively simple. You start with 1,024 small programs, each 64 bytes long, filled with random data. These programs use an extended version of Brainfuck called BFF, where only 10 out of the 256 possible byte values are valid instructions. The rest are treated as no-ops.
Each “interaction” picks two programs at random, concatenates them into a 128-byte tape, and runs them as BFF. The tape is then split back into two 64-byte programs which replace the originals. That’s it. No scoring, no tournaments, no survival of the fittest. Just programs blindly modifying each other.
The key instructions that matter here are . (copy from read head to write head) and , (copy from write head to read head). Combined with loops ([ and ]) and head movement operators, these allow a program to, in principle, copy its own code onto its neighbor.
The fascinating part is that nobody tells the programs to self-replicate. The instruction set merely allows copying. Whether it happens is entirely up to chance and the dynamics of the system.
What Happens
For thousands of epochs, not much. The random programs mostly execute a few hundred operations each before hitting the step limit or running off the end of the tape. The soup is noisy and incoherent — what you’d expect from random bytes.
Then, without warning, something changes.
A program stumbles into a configuration that copies itself onto its interaction partner. This replicator starts spreading through the population. Within a few hundred epochs, it dominates the entire soup. The computational intensity, which is the number of operations executed per interaction, shoots up as programs now contain functional loops that actually do something. Unique program lineages collapse from tens of thousands to a handful.
The paper calls this moment “gelation.” I’d call it just a little bit eerie. And cool. Pretty cool.
Building the Replication
The experiment is implemented in C (with OpenMP for parallelization) wrapped in Python for orchestration and plotting. The core BFF interpreter runs each interaction, and the Python layer manages the population, collects metrics, and generates both static and interactive visualizations.
The C engine handles the heavy lifting. Each epoch runs 1,024 interactions, and a typical run does 50,000 epochs, which is 51.2 million interactions total. On a 12-thread desktop this takes a few minutes per seed. For an overview of the setup and instructions to run it yourself, see the GitHub repository.
The Results
For the results used in this blog post I ran 5 seeds, each for 50,000 epochs (51.2 million interactions per seed). Here’s the interactive chart of mean operations per interaction across all runs. Click on any seed in the legend to toggle it on or off:
Every single seed shows the same pattern: a gradual rise from baseline noise (~700 ops) as proto-replicators start appearing, followed by sustained high computational activity (6,000 to 12,000 ops) as self-replicators take hold and continuously execute their copy loops.
Another way to observe what’s happening is through compressibility. When a replicator dominates, the soup is full of nearly identical programs, which compress very well. When the population is more diverse, for example during a transition or after a crash, the data becomes harder to compress. Compressibility dips are essentially the fingerprint of regime change in the soup. The bigger the dip, the more dramatic the upheaval.
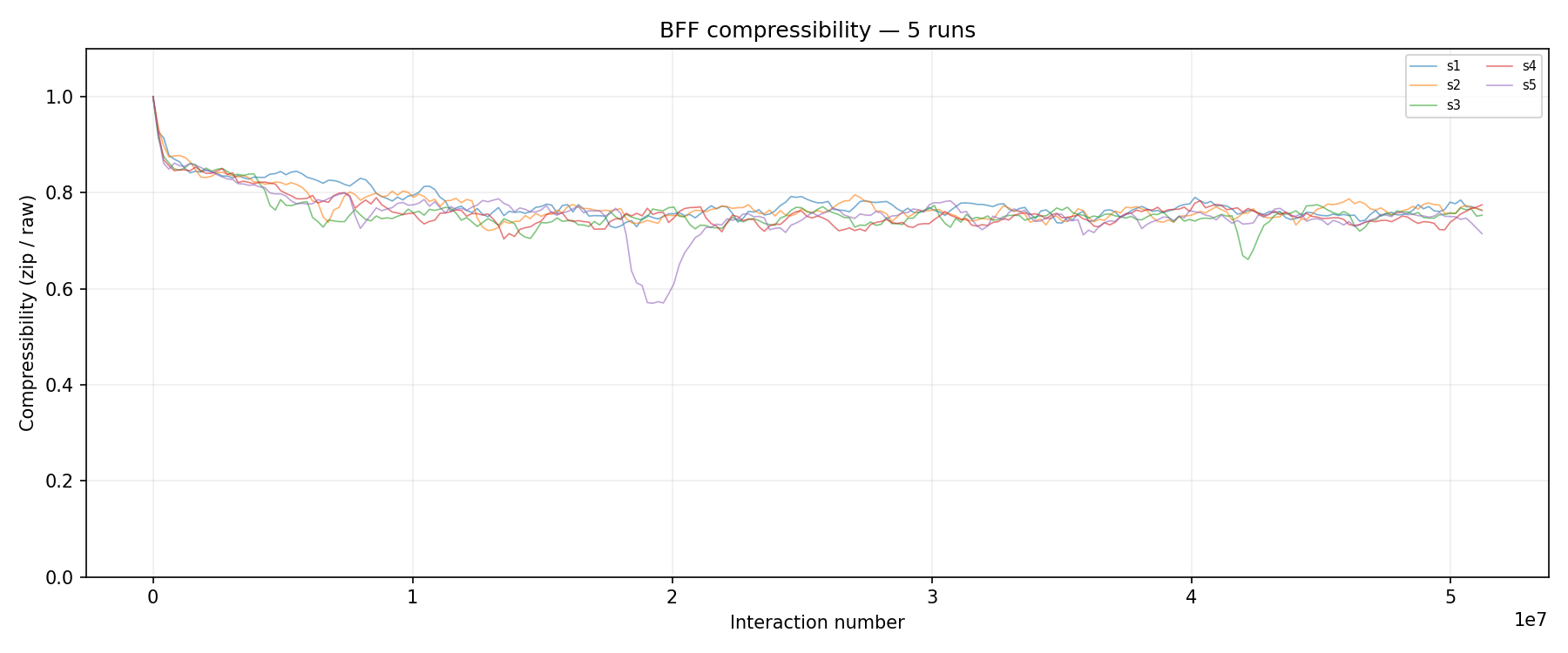 Compressibility (zip size / raw size) across all 5 seeds. Seeds 3 and 5 stand out with noticeable dips. Let’s have a look at those two in more detail.
Compressibility (zip size / raw size) across all 5 seeds. Seeds 3 and 5 stand out with noticeable dips. Let’s have a look at those two in more detail.
Seed 5 has a dramatic dip around 2.0e7 interactions and seed 3 shows a subtler one around 4.0e7. Toggle those two seeds in the interactive chart above and you’ll see corresponding events in the mean ops as well. The compressibility chart, the interactive ops chart, and the scatter charts below all tell the same story from different angles.
Seed 5: Crash, Compete, Rebuild
Seed 5 tells the most dramatic story out of all the runs. Toggle it on in the interactive chart above and you’ll see a distinctive V-shaped dip at around 20 million interactions where mean ops plummet from ~6,000 back down to ~1,000 before rebuilding. The scatter chart below shows the same run from a different perspective. Look at the compressibility subplot at the bottom:
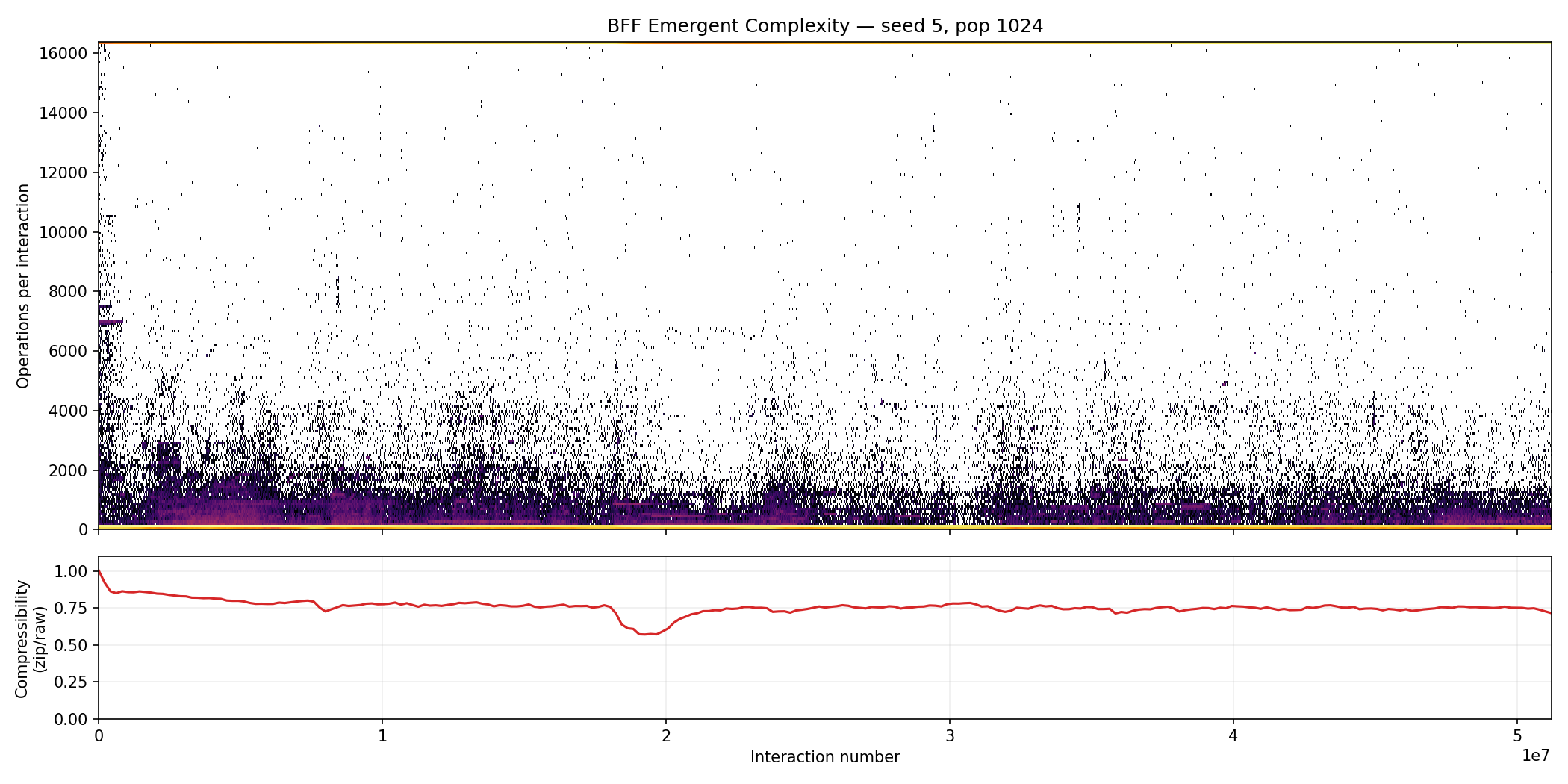 Seed 5: Notice the compressibility dip at around 2.0e7 interactions. This is the same crash visible in the interactive chart and the multi-run compressibility plot above.
Seed 5: Notice the compressibility dip at around 2.0e7 interactions. This is the same crash visible in the interactive chart and the multi-run compressibility plot above.
For the first 15 million or so interactions, a replicator gradually takes hold and ops climb steadily. Then, around interaction 20 million, something catastrophic happens. The dominant replicator was destroyed, likely corrupted by a mutant interaction that broke its copy loop. The compressibility dips at exactly the same point because the population suddenly becomes more diverse. It’s a mix of dead replicator fragments, random debris, and whatever new proto-replicator is starting to spread.
But then it rebuilds. A new replicator starts spreading and by 50 million interactions the ops are higher than before.
The final tape dump reveals the aftermath. Three competing lineages survived:
1
2
3
4
5
6
7
8
51,200,000 interactions
44 unique tokens, 1024 programs
977: 2E40 < < > , ,< << < < ,< .. <
977: 2E40 - ..+. ..>, < < ,,, <<,< < < > >>> > >>>> < < <
21: 3800 . ---,> < ,,, [
21: 3800 - +[[[ ][[ ][[>][[][[][[][[][[][[ ][[ ][[ ][[ ][[ ][[ , ,
21: 2BA4 [] [ [ [ [ , <<
21: 2BA4 ] - , -,,,,, ,,,,,,,,, ,,,,,,,,,,,,,,,,, , , , <
The dominant lineage (2E40) controls 977 of 1,024 programs (95.4%), but lineages 3800 and 2BA4 each hold 21 programs. Only 44 unique tokens remain out of the original 65,536. Each lineage has its own distinct code structure with different copy strategies and loop patterns. It’s an ecosystem with a dominant species and two smaller populations holding on.
Seed 3: Total Domination
Seed 3 took a very different path. Toggle it on in the interactive chart and you’ll see a steady rise followed by a sharp spike and drop at around 40 million interactions. It’s not the catastrophic collapse that seed 5 went through, but something clearly happened. The scatter chart shows the corresponding compressibility signal:
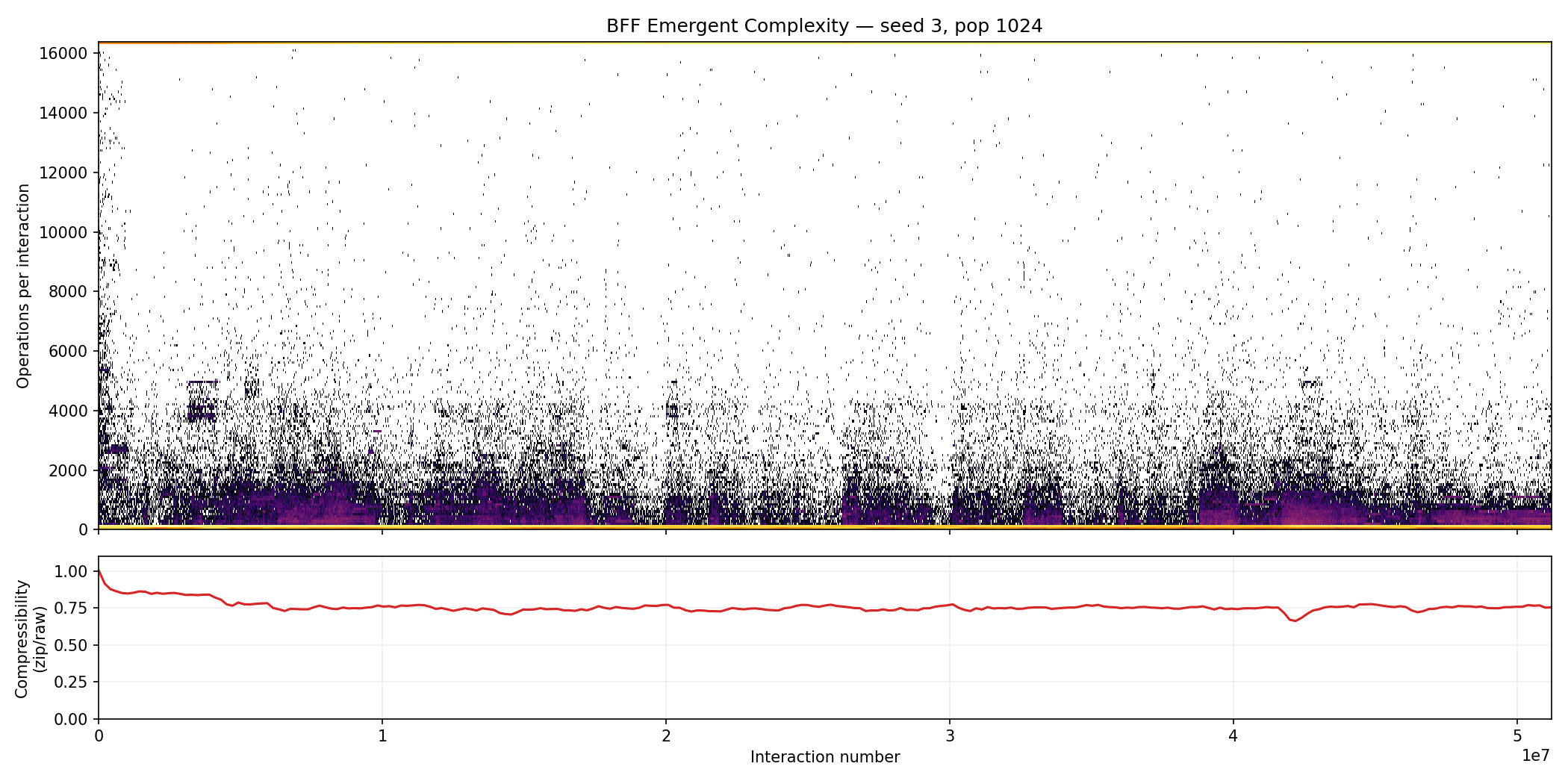 Seed 3: Look at the compressibility subplot at around 4.0e7 interactions. The dip is subtle but it lines up perfectly with the ops spike in the interactive chart.
Seed 3: Look at the compressibility subplot at around 4.0e7 interactions. The dip is subtle but it lines up perfectly with the ops spike in the interactive chart.
The compressibility dip is much smaller than seed 5’s, which tells us this was a smoother transition. Most likely a more efficient mutant replicator displaced its predecessor. The dip is small because the new replicator probably descended directly from the old one and was structurally similar, so the soup never became truly diverse during the handoff.
The result is total domination. Out of 1,024 programs, 1,023 ended up belonging to a single lineage (BEC0). Only 209 unique tokens remained out of the original 65,536. One replicator essentially consumed the entire population.
The tape dump tells the story. Before any interactions, the soup looks like the below. Pretty sparse, random BFF characters scattered across mostly empty bytes:
1
2
3
4
5
6
7
8
0 interactions
65,536 unique tokens, 1024 programs
1: 0000 < + }
1: 0040 {
1: 00C0 - + { > .
1: 0100 < < - +
1: 0380 - } }
1: 03C0 [ ] >
After 51.2 million interactions:
1
2
3
4
5
6
51,200,000 interactions
209 unique tokens, 1024 programs
1023: BEC0 { [] [ - [ > [ ,[, [ < [> -,, ,,< < <
1023: BEC0 > >>< > <+ + > < , <<<<
1023: BEC0 [ ] >> , , < << +< +< , ,,><,
1: B566 [[] [[[[[[[[[[[[ [[[[[[[[[[[ [[[[[[[[[<,, < <
1,023 out of 1,024 programs share lineage BEC0. The code is dense with copy operators (, and .), loops ([ ]), and head movements. This isn’t random anymore! Instead it’s structured, functional code that actively replicates itself. The lone holdout (lineage B566) is a degenerate program full of unmatched brackets. That part is essentially dead code that hasn’t been overwritten yet.
Comparing the two seeds is fascinating. Seed 5 went through a catastrophic collapse and rebuilt into a contested ecosystem with three lineages. Seed 3 had a smooth, uncontested rise to near total monoculture. Same experiment, same parameters, completely different evolutionary narratives. Probably one that running for more epochs would answer. I’ll try to get some more compute time on a proper cluster later. For now this has been executed on my gaming PC which by now is fairly old.
So What Does This Mean?
The experiment demonstrates that self-replication and with that we can observe a form of primitive “life” emerge. This type of “life’ doesn’t require intelligent design or even evolutionary pressure. It requires only three things:
- An instruction set that permits copying
- Random initial conditions
- Enough interactions for the improbable to become inevitable
That last point is key. With 51.2 million random interactions among 1,024 programs, the combinatorial space is vast enough that a self-replicating configuration will eventually be stumbled upon. And once it exists, it has an inherent advantage: it makes copies of itself. No fitness function needed for this to happen. Replication itself is the fitness function.
The Bigger Picture: Intelligence in the Fabric
This experiment sits at the intersection of several provocative ideas about the nature of intelligence and reality. This section references some pretty wild ideas but they’re really interesting to think about.
Xenobots: Life Finds a Way
In 2021, researchers at Tufts University and the University of Vermont created Xenobots — tiny “robots” made from frog embryo cells. These cells, removed from their normal context, spontaneously organized into new forms and exhibited behaviors never seen in nature, including a novel form of self-replication where they gather loose cells into new Xenobots. No genetic modification. No programming. Just cells freed from their usual biological constraints, discovering new ways to be.
The parallel to our BFF experiment is striking. In both cases, simple components with no explicit instructions to self-replicate nonetheless find a way to do so. The capacity for complex, “intelligent” behavior seems to be lurking in the substrate itself, waiting for the right conditions.
Hoffman: The Desktop of Reality
Donald Hoffman, a cognitive scientist at UC Irvine, takes this even further with his Fitness Beats Truth theorem. His mathematical proof shows that organisms tuned to perceive reality accurately will never be more fit than organisms of equal complexity that perceive none of reality but are tuned to fitness payoffs instead. In other words, evolution doesn’t select for truth but for useful fictions. The “reality” we observe as human beings is not an accurate reflection of reality as it really is.
If Hoffman is right, then what we perceive as “reality”, basically space, time, objects, is more like a desktop interface. The icons on your screen don’t resemble the actual electrical patterns in your computer’s circuits. They’re a simplified interface that helps you get things done. Similarly, our perception of the world might be a species-specific interface optimized for survival, not for accuracy.
This has a remarkable implication for experiments like this BFF simulation. If the fundamental nature of reality is not what we perceive, then perhaps the tendency toward self-organization, complexity, and even intelligence isn’t an emergent property of matter. Instead it might be a fundamental feature of whatever the underlying substrate actually is. The BFF experiment might not be creating something new. It might be revealing something that was always there.
Plato’s Cave, Revisited
The ancient idea that we perceive shadows on a cave wall rather than reality itself is getting unexpected support from multiple directions. Hoffman’s mathematics, the Xenobots’ spontaneous intelligence, and the emergence of self-replicating code from pure noise all point in the same direction: complexity and organization arise with suspicious ease, almost as if the universe is predisposed toward them.
Whether this means intelligence is somehow woven into the fabric of reality, or whether self-replication is simply such a powerful attractor that any sufficiently rich system will find it is a question nobody has fully answered yet. But I find it pretty awesome that 1,024 tiny programs full of random garbage can, given nothing more than time and interaction, spontaneously organize into structured, self-replicating code.
No designer needed. No fitness function. Just noise, time, and the right set of instructions.
Try It Yourself
The full code is available on GitHub. With a C compiler and Python 3.10+, you can run your own experiments and see the phase transition on your own hardware. A 12-thread desktop can run 50,000 epochs in a few minutes.
References
- Agüera y Arcas et al., Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction, arXiv:2406.19108 (2024)
- Hoffman, D., Fitness Beats Truth, Psychonomic Bulletin & Review
- Kriegman et al., Kinematic self-replication in reconfigurable organisms, PNAS (2021)
- ricky0123, Reproducing the results of a computational life experiment