一部のお客様は、AWSでリージョンをまたいだディザスタリカバリ(DR)を必要としていますが、別のリージョンにフェイルオーバーする際にIPアドレスが変更されるという課題に直面することがよくあります。この変更により、DRポリシーで保護されているインスタンス上で実行されているサービスへの外部アクセスが中断される可能性があります。
Nutanix Cloud Clusters (NC2) は、この課題に対応するためのDR機能をビルトインしており、リージョン間でフェイルオーバーする際にもIPアドレスを一貫して維持することができます。さらに、NC2ではCPUのオーバープロビジョニングが可能であるため、NC2への移行後にコンピュートコストを削減できる可能性もあります。ただし、DR中にIPアドレスを保持できるのは、すでにNutanixクラスター上に存在しているワークロードのみであるため、EC2インスタンスは先に移行しておく必要があります。
無料の移行ツールであるNutanix Moveを使用すれば、Amazon EC2からNutanix Cloud Clustersにワークロードを移行することができます。ただし、現時点ではIP保持をサポートしていません。このブログでは、移行中に一貫したIPアドレスを維持するための工夫を紹介しますが、MACアドレスが変更されることには注意してください。その後、NC2はNutanix DRソリューションの一部としてリージョン間フェイルオーバー中にIPアドレスを保持します。それでは始めましょう!
テストで使われていたソフトウエアバージョン
| AOS | 6.10 |
| Prism Central | pc.2024.2 |
ソリューションアーキテクチャ
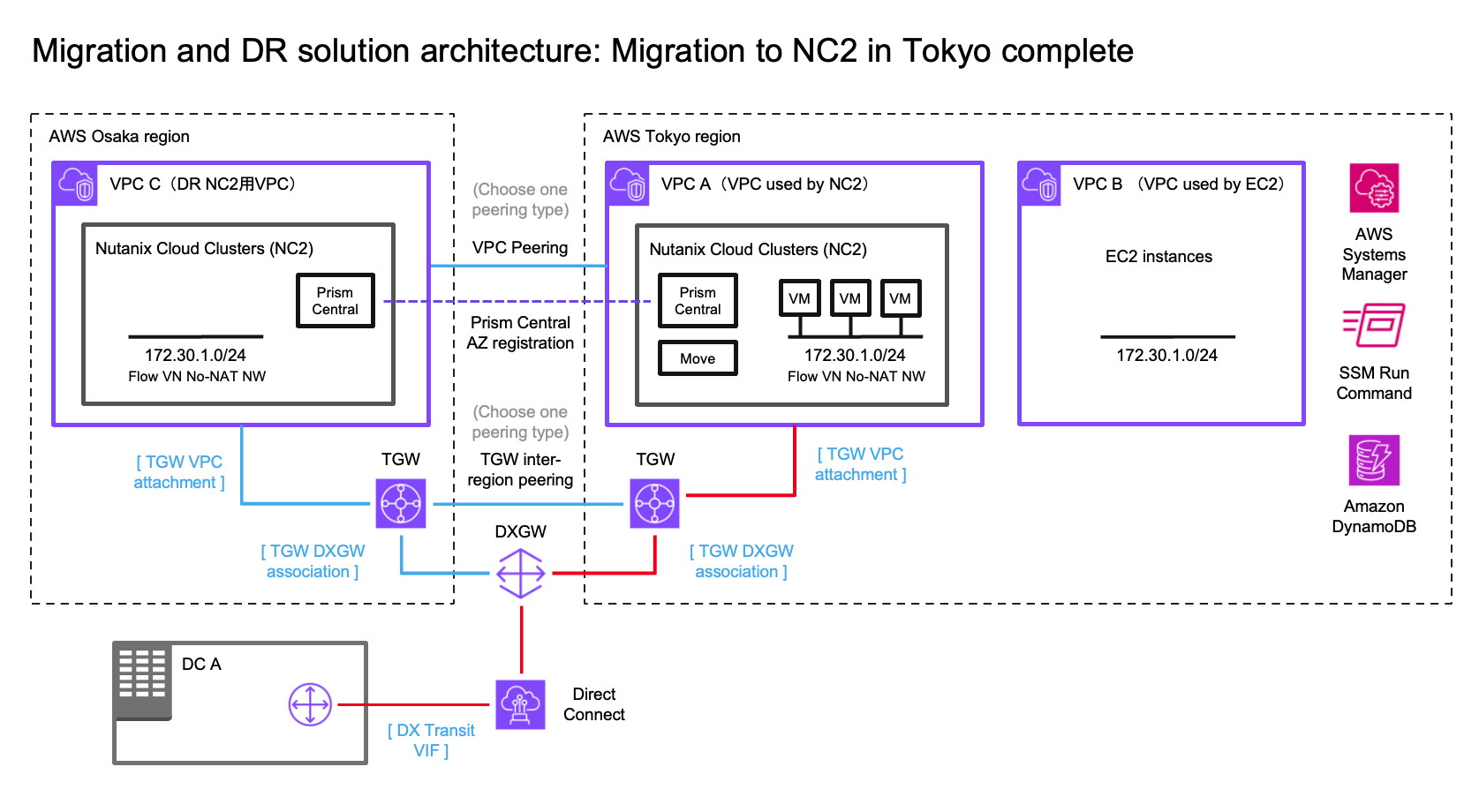
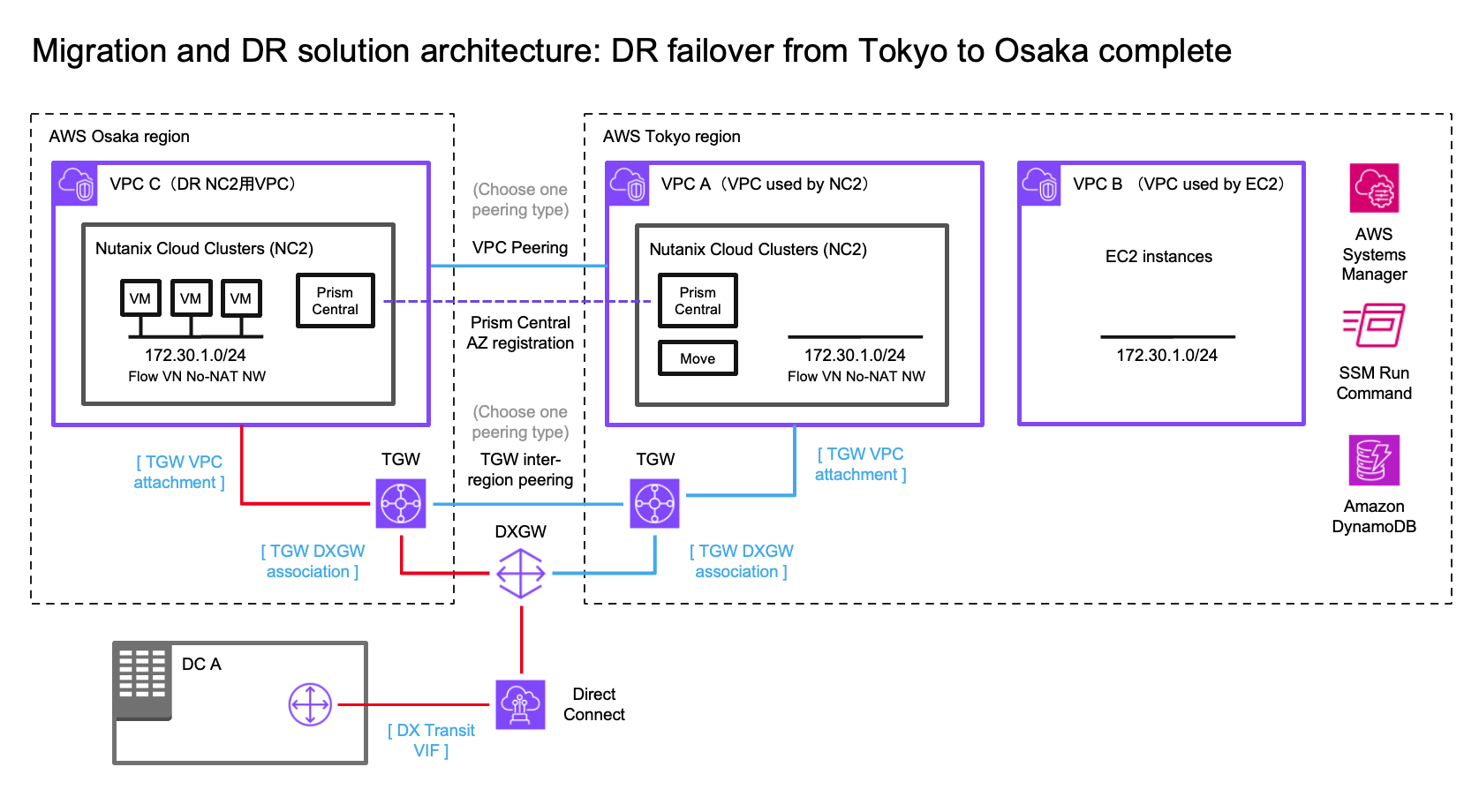
この例では、オンプレミスのデータセンター(DC)、DRポリシーでカバーするAWS VPC(別のリージョンにフェイルオーバーしてもIPアドレスが変更されないようにする)にあるEC2インスタンス、そして2つのNC2クラスター(東京リージョンと大阪リージョン)を使用します。この例では、AWSの東京リージョン(ap-northeast-1)をプライマリリージョン、大阪リージョン(ap-northeast-3)をディザスタリカバリの場所として使用します。
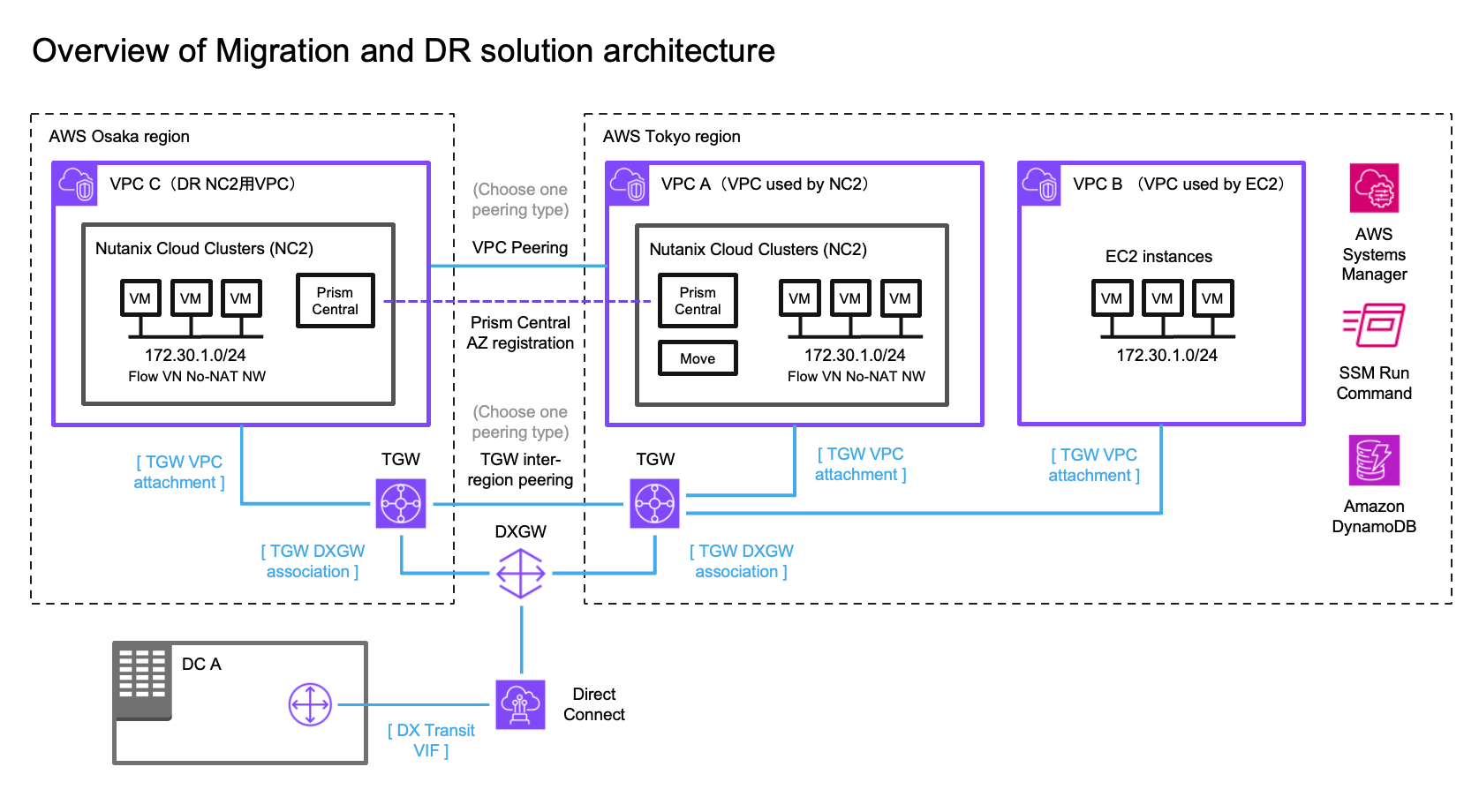
オンプレミス環境との接続をDirect Connectで示していますが、このソリューションのテストはすべて各リージョンのTGWに接続されたS2S VPNで行われています。DR間の接続は、クロスリージョンVPCピアリングまたは2つのTransit Gateway (TGW) のピアリングを使用して行うことができます。
ネットワーキング
移行されたEC2インスタンスのIPアドレスを保持するために、Flow Virtual Networking (FVN) を使用して、NC2上にオーバーレイのNATなしオーバーレイネットワークを作成します。このネットワークのCIDR範囲は、EC2インスタンスが接続されている元のサブネットの範囲と一致させます。このオーバーレイネットワークは、東京および大阪のNC2クラスターの両方に作成されます。これにより、VMがフェイルオーバーされても同じCIDR範囲を持つネットワークに接続できます。
オンプレミスDCがこれらのVMにアクセスできるようにするために、プロセス全体でルートテーブルを変更します。これにより、移行されたEC2インスタンスの場所に関係なく、それらを指すルートを維持できます。
Terraform / Open Tofu を使用したVPCとTGWの自動作成
このソリューションを試してみたい場合、VPCやTGW、ルーティングをデプロイするためのTerraform / Open Tofuテンプレートを以下で入手できます:
https://github.com/jonas-werner/aws-dual-region-peered-tgw-with-vpcs-for-nc2-dr
リージョン間接続のためのピアリングタイプの選択
一般的に、以下のように考えられます:
- VPCピアリング: データ転送コストがやや高いものの、直接的な接続のシンプルさが求められる低トラフィックのシナリオに最適です。
- TGWピアリング: 高トラフィック環境や複雑なアーキテクチャに適しています。集中管理や低いデータ転送料金が、TGWアタッチメントの追加コストを上回ります。なお、トラフィックは2つのTGWを通過しますが、ピアリングインターフェイスではデータ転送料金は発生しないため、データは1回だけ課金されます(東京リージョンではおおよそ0.02セント/GiB)。
IP保持のための回避策
冒頭で述べたように、Nutanix Move仮想アプライアンスはEC2からNC2への移行に非常に優れていますが、現時点では移行されたワークロードのIPアドレスを保持する機能はありません。この課題を回避するために、以下の手順を実施します:
- 移行前
AWS Systems Manager (SSM) を使用して、移行対象のインスタンス上でPowerShellまたはBashスクリプトを実行します。このスクリプトは、EC2インスタンスのID、ホスト名、およびローカルIPアドレスを取得し、その情報をDynamoDBテーブルに保存します。 - 移行中
Nutanix Moveを使用して、EC2からNC2にインスタンスを移行します。この間にIPアドレスは変更されますが、移行先はEC2インスタンスが接続されていた元のネットワークのCIDR範囲と一致するFVNオーバーレイネットワークです。 - 移行後
DynamoDBに保存した情報をテンプレートとして使用するPythonスクリプトを実行します。このスクリプトは、Nutanix Prism Central APIに接続し、既存のネットワークインターフェイスを削除し、正しい(元の)IPアドレスを持つ新しいインターフェイスを各インスタンスに追加します。
これらの手順を経て、インスタンスがNC2に移行された後は、東京と大阪のリージョン間でのDR設定が簡単に行えるようになります。
このブログに使われているスクリプトは以下の GitHubページからダウンロードできます:
https://github.com/jonas-werner/EC2-to-NC2-with-IP-preservation/tree/main
ステップ1: EC2インスタンスのIPアドレスを取得
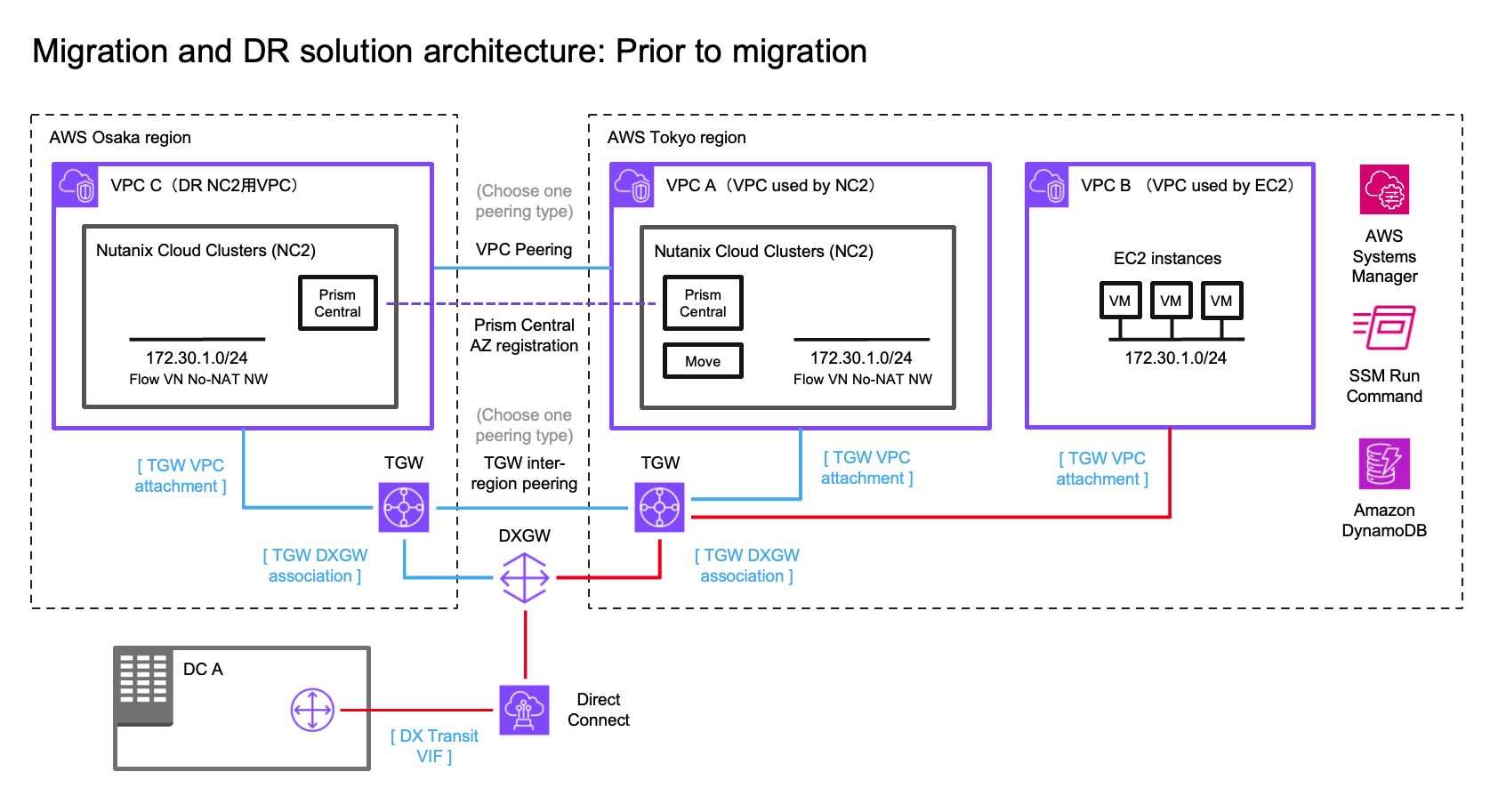
このステップでは、EC2からNC2への移行の準備を行います。ネットワーク、ワークロード、および172.30.1.0/24ネットワークへのルートの初期状態は、以下の図の赤い線で示されています。
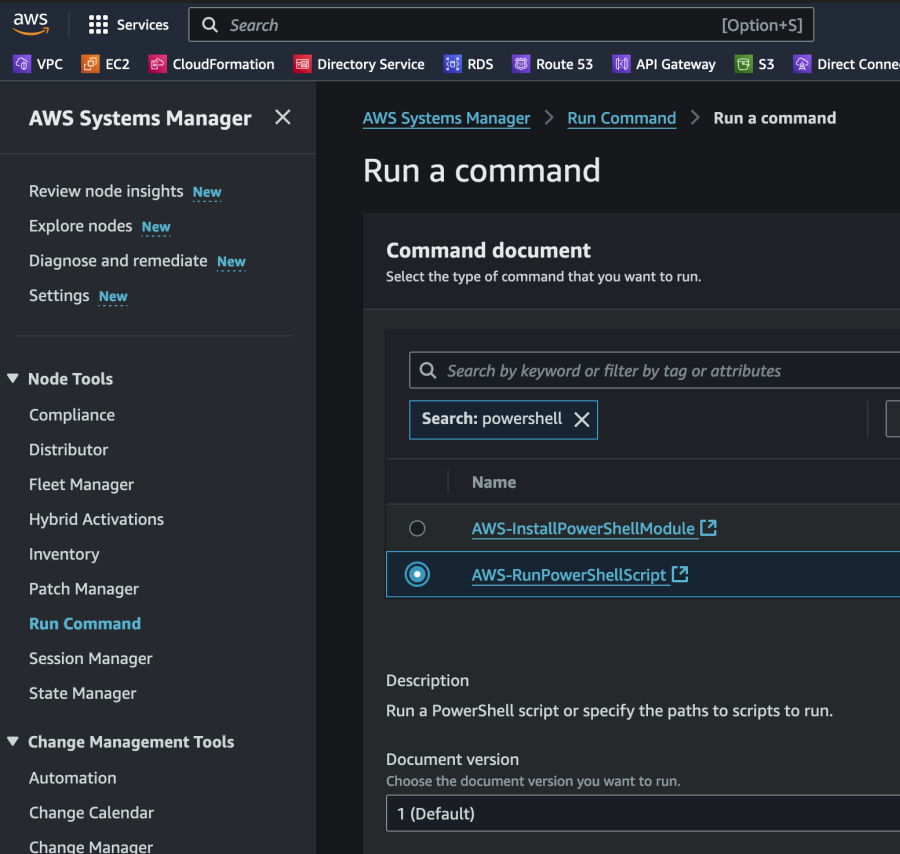
最初に、EC2インスタンスに関する情報を収集し、その情報をDynamoDBに保存します。効率を重視して、SSM Run Commandを使用してPowerShellスクリプトを実行します。これにより、WindowsおよびLinuxワークロードの両方を1回または2回の操作で簡単に処理できます。この例では、単一のWindows Server 2019 EC2インスタンスをテスト対象として使用します。
まず、この情報を保持するためのDynamoDBテーブルを作成します。このテーブルには特別な要件はなく、SSMがスクリプトを実行する際にアクセスできれば十分です。もちろん、SSMコマンドを実行する際に使用するIAMロールにDynamoDBへのアクセス権を付与する必要があります。そのため、以下のような権限を標準のSSMロールに追加します:
{
"Sid": "AllowDynamoDBAccess",
"Effect": "Allow",
"Action": [
"dynamodb:PutItem"
],
"Resource": "arn:aws:dynamodb:<your-aws-region>:<your-aws-account>:table/<dynamodb-table-name>"
},インスタンス名をメタデータから収集するために、EC2コンソールで「インスタンスメタデータにタグを許可」設定を有効化します。この設定は、移行後にNC2でインスタンスを検索する際に「Name」タグをキーとして使用するために重要です。他の方法(たとえばインスタンス名自体を使用する)も可能ですが、このケースではEC2の「Name」タグを使用します。これは、移行後も同じタグがNC2に表示されるためです。
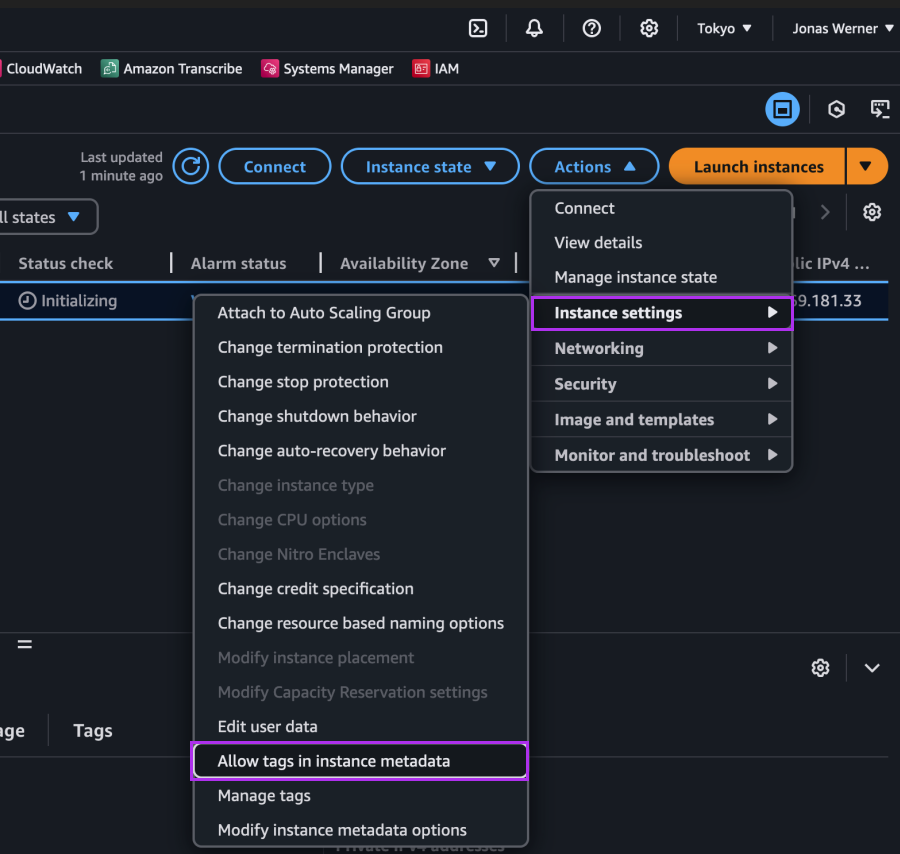
SSM Run Commandを使用して、インスタンス上でスクリプトを実行します。以下のコマンド例を参照してください:
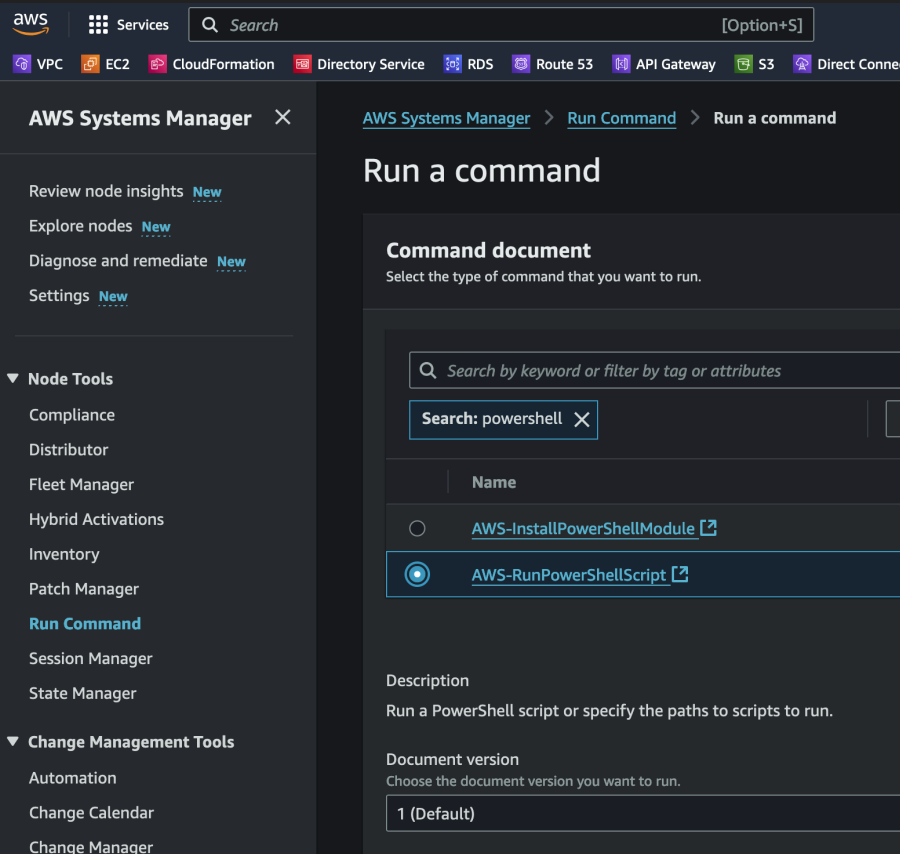
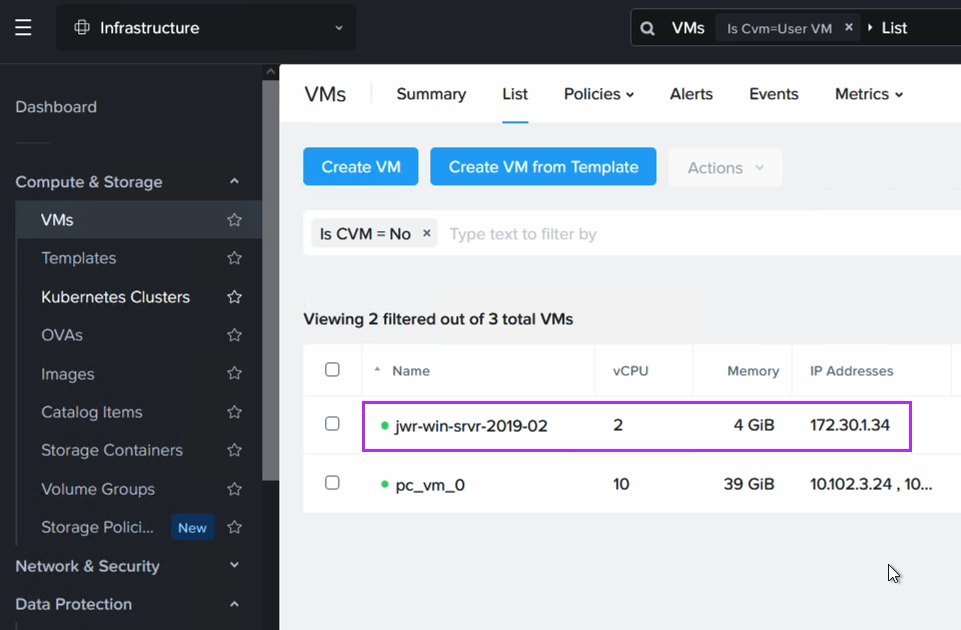
スクリプトの実行後、Windows EC2インスタンスのエントリがDynamoDBに表示されます。これには、インスタンスID、ホスト名、およびIPアドレス(例: 172.30.1.34)が含まれます。このIPアドレスは保持したいアドレスです。
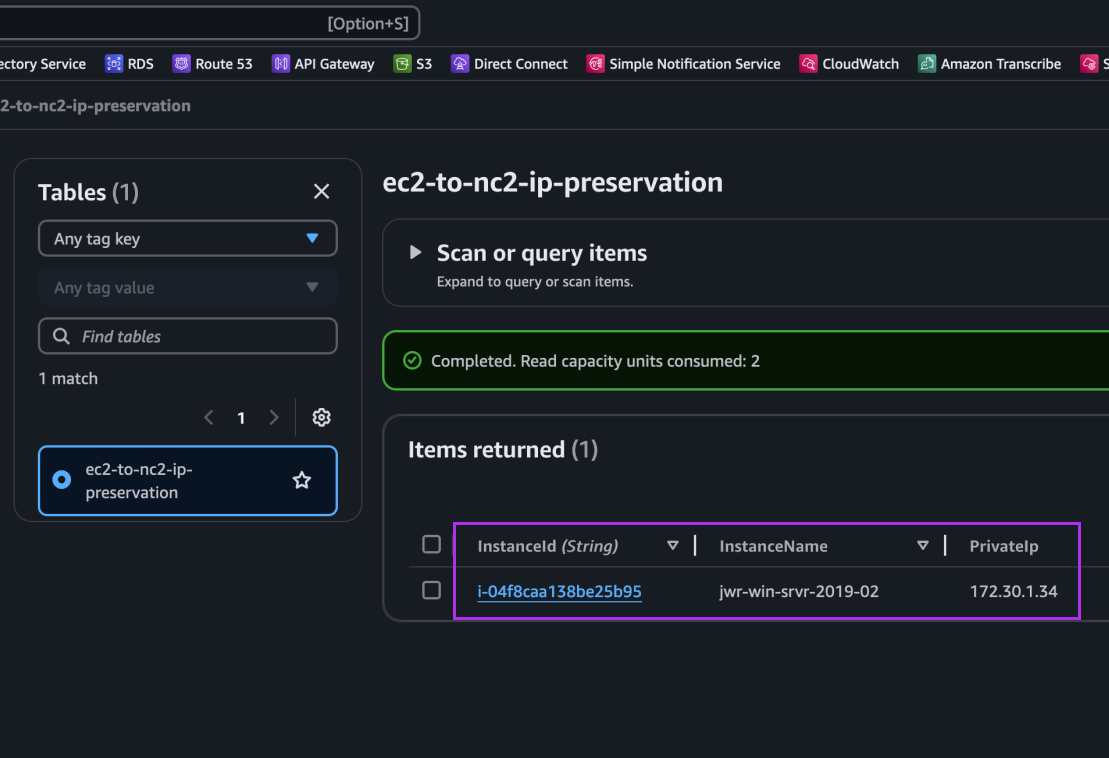
次に、EC2 から NC2 への移行を実行します。
ステップ2: EC2からNC2への移行
次に、EC2からNC2への移行を実施します。この移行では、Nutanix MoveをNC2クラスター上に展開済みである必要があります。また、FVNオーバーレイネットワークを作成しており、そのCIDRはEC2インスタンスが接続されていた元のサブネットと一致していますが、DHCPの範囲は現在そのサブネットで使用されているIPアドレスを避けるよう設定されています。
Moveには、NC2クラスターとAWS環境が移行元および移行先として設定されています。
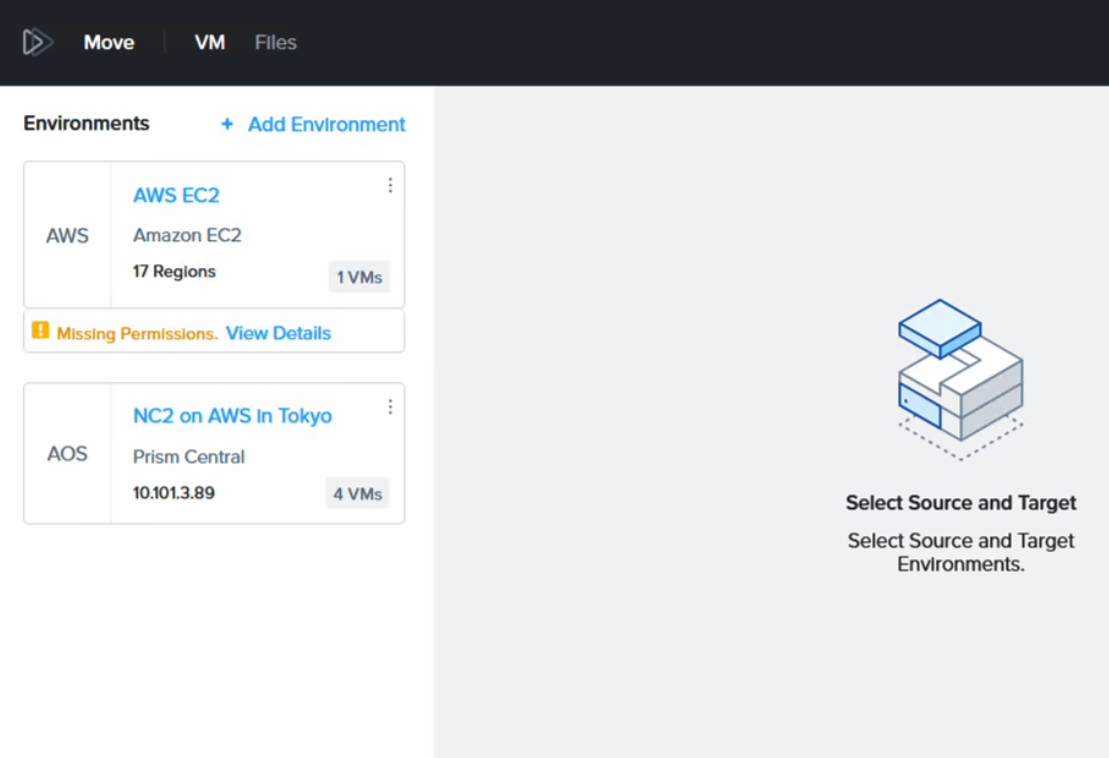
「Missing Permissions」という警告が表示される場合がありますが、これはAWS IAMポリシーで、EC2への移行を許可していないためです。しかし、EC2からの移行のみを行う場合、この警告は無視して構いません。必要なIAMポリシーの詳細は、Moveのマニュアルをご確認ください。
移行後、VMは異なるIPアドレスを持つようになります(移行先のFVNサブネットのDHCP範囲から取得されます)。
次のステップで、Pythonスクリプトを使用して元のIPアドレスに戻す処理を行います。
ステップ3: EC2インスタンスが元々持っていたIPアドレスに戻す
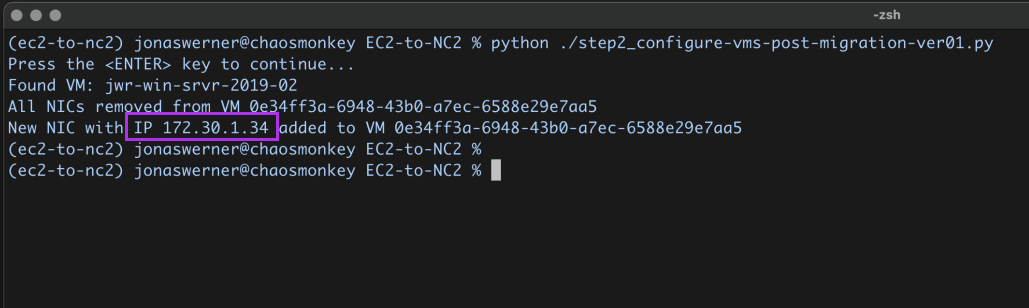
次に、Pythonスクリプトを実行して、DynamoDBに保存されたインスタンス名を参照し、それをNC2のVM名と照合します。その後、Prism Central APIを使用して既存のネットワークインターフェイスを削除し、新しいネットワークインターフェイスを追加します。この新しいインターフェイスには、元の静的IPアドレスが設定されます。
このスクリプトはGitHubからダウンロードできます。スクリプトを実行するには、Prism Centralのユーザー名とパスワードを環境変数としてエクスポートしてください。また、Prism CentralのIPアドレス、使用するサブネット名、AWSリージョン、DynamoDBテーブル名をお使いの環境に合わせて更新してください。
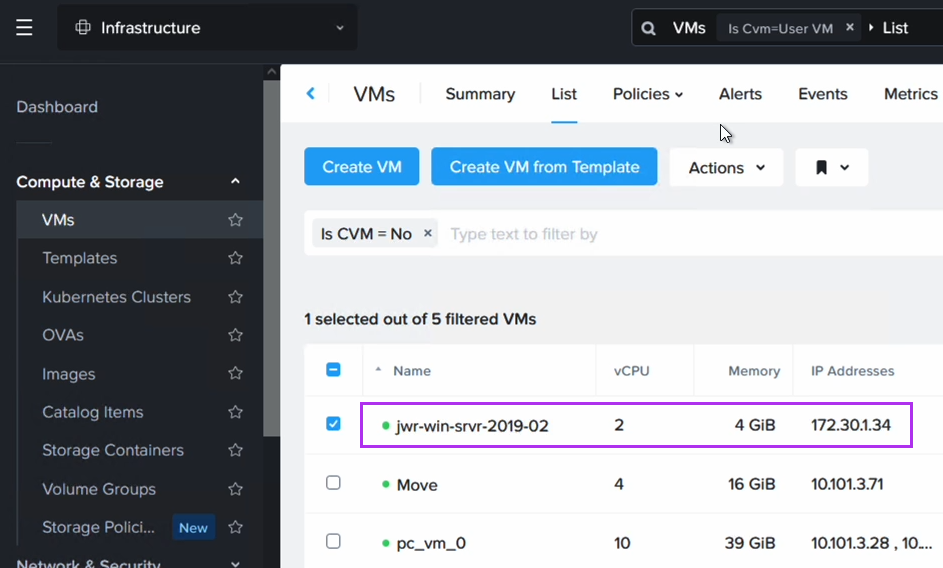
スクリプトを実行すると、VMが元のIPアドレスを取得したことを確認できます。ただし、このプロセスではNICが置き換えられるため、IPアドレスは同じですが、MACアドレスは変更されています。
EC2からNC2への移行後の東京リージョンでのルーティング
VMがNC2上に存在するようになったため、トラフィックが元のEC2インスタンスではなく、このVMに向かうようルーティングを更新する必要があります。これは、EC2 VPCをTGWから切断し、NC2 VPCを指すようにTGWに静的ルートを追加することで実現します。このサブネットはすでにDXGWの「許可されたプレフィックス」として存在するはずなので、この部分は変更する必要はありません。
赤で強調されたアタッチメントは、172.30.1.0/24サブネットへのアクティブルートを示しており、現在はNC2 VPCを指すように変更されています。このサブネットはFVNのNo-NATサブネットであるため、NC2 VPCのルートテーブルに表示されます。
移行作業のまとめ
これでEC2インスタンスはNC2に移行されました。IPアドレスは保持されており、AWSとオンプレミスDC間のルーティングが更新されたため、オンプレミスのユーザーは、通常通り移行されたインスタンスにアクセスできます。実際、移行のメンテナンスウィンドウ、NC2でのVMの電源オン、およびルーティングの切り替えを除けば、これらのユーザーは元のEC2インスタンスが別のプラットフォームで動作するようになったことに気付くことはほとんどありません
東京と大阪のNC2クラスター間でのDR構成
ここまでで、東京リージョンのNC2クラスターにEC2インスタンスを移行し、IPアドレスを保持した状態でオンプレミス環境と通信できるようになりました。次に行うのは、東京と大阪の2つのNutanixクラスター間で災害復旧(DR)構成を設定することです。DRはNutanixの標準機能として組み込まれているため、この設定は非常に簡単です。Prism Centralインスタンスをリンクし、大阪側でもFVNオーバーレイネットワークを作成して、フェイルオーバー後も同じCIDR範囲を使用できるようにします。
災害復旧機能を有効にした後、Prism Centralを使用してDRプランを簡単に作成できます。
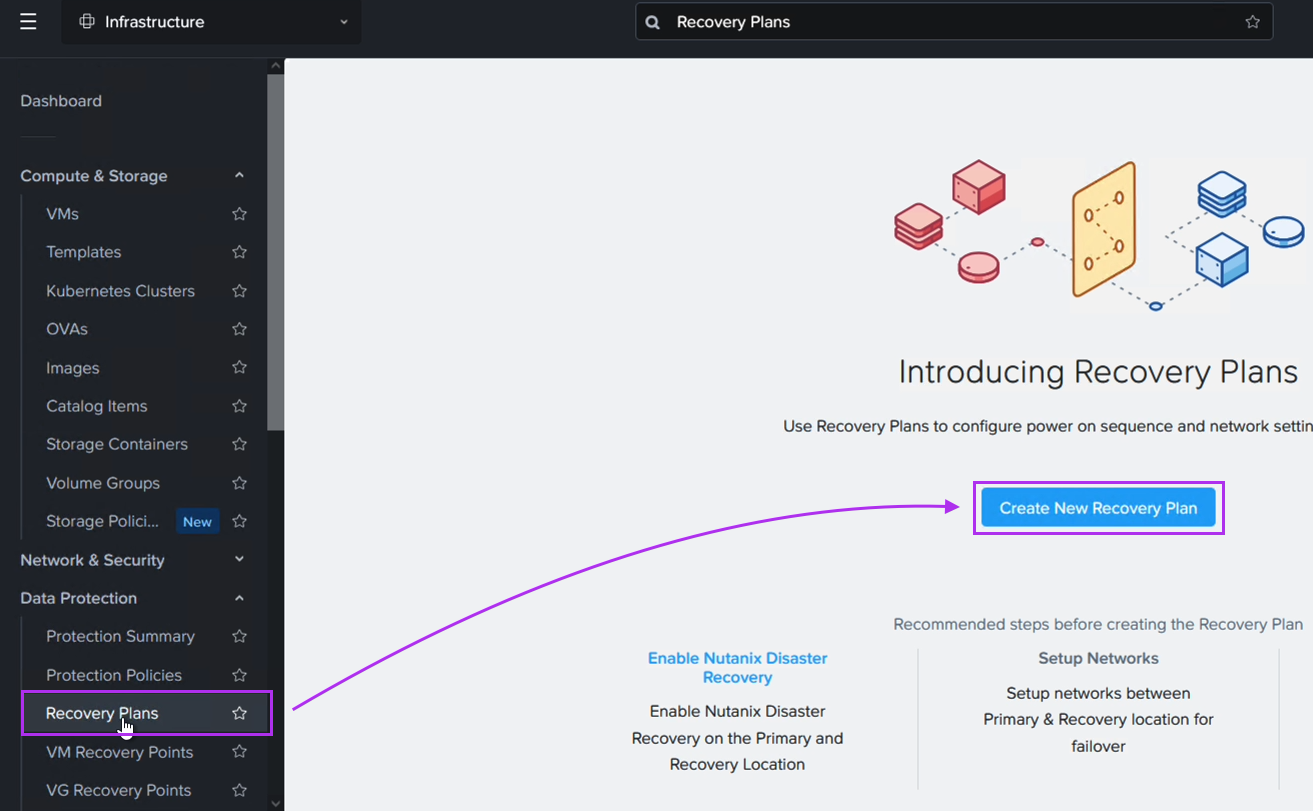
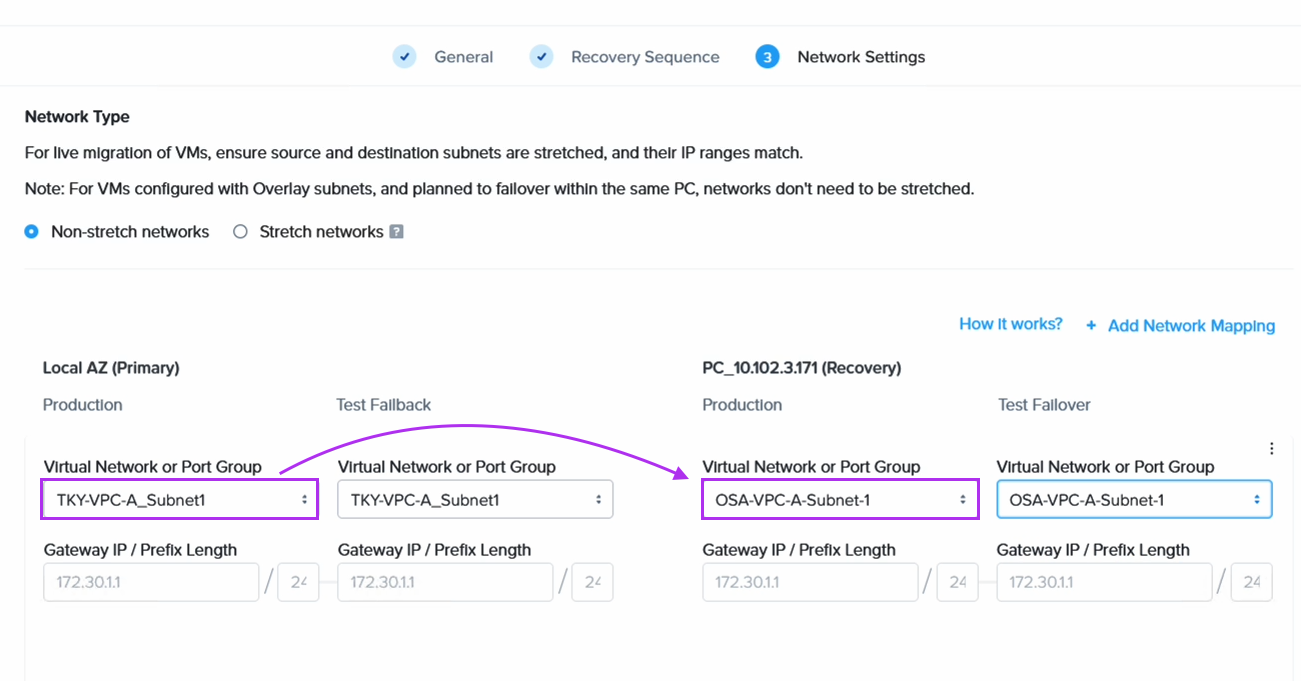
DRプランを作成する際、東京ネットワーク上のVMが大阪DRサイト上の対応するネットワークにフェイルオーバーするように設定します。
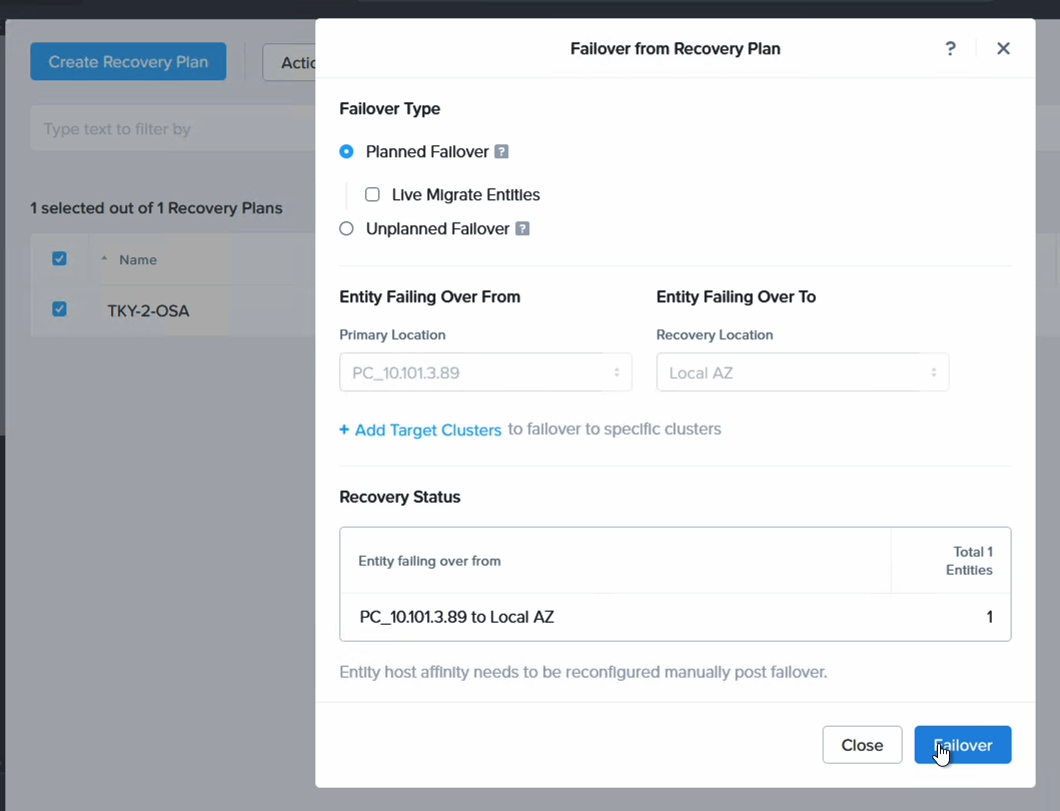
最後に、東京のNC2クラスターから大阪のNC2クラスターにVMをフェイルオーバーします。
フェイルオーバー後、VMが大阪で正常に起動していることを確認できるだけでなく、期待通りにIPアドレスが保持されていることも確認できます。
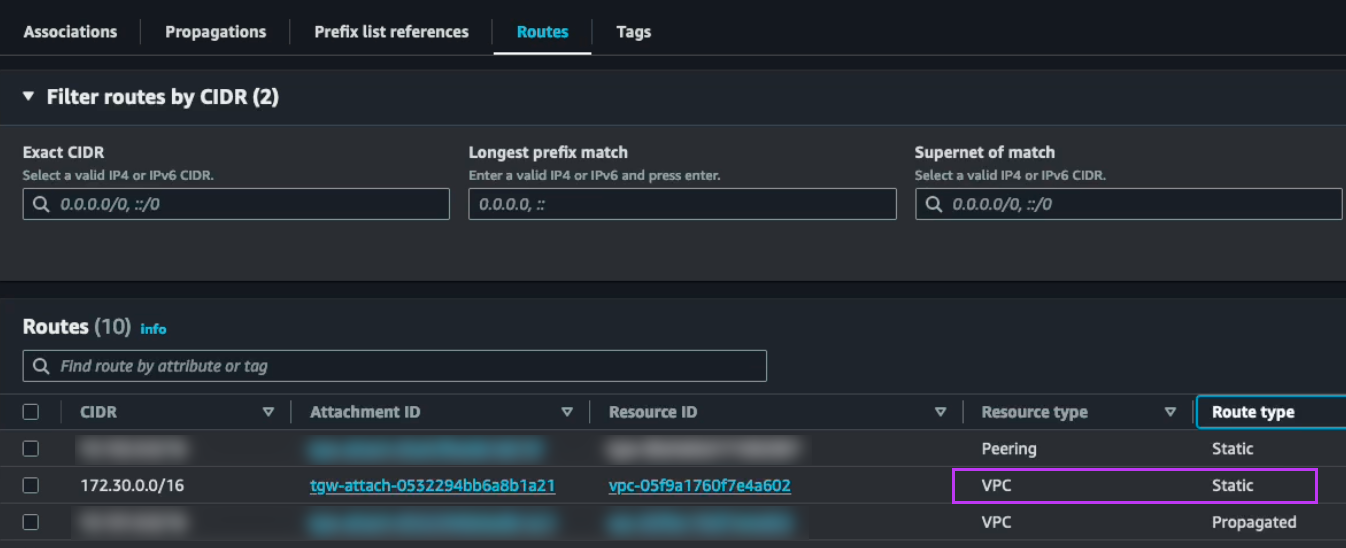
東京から大阪へのルーティング更新
東京から大阪へのフェイルオーバーが完了したら、172.30.1.0/24ネットワークを指すルートを更新し、大阪を指すようにTGWの設定を変更します。これにより、以下のようなネットワーク構成になります。
大阪TGWでは、172.30.0.0/16ネットワークを大阪のNC2 VPCに向けた静的ルートを作成します。
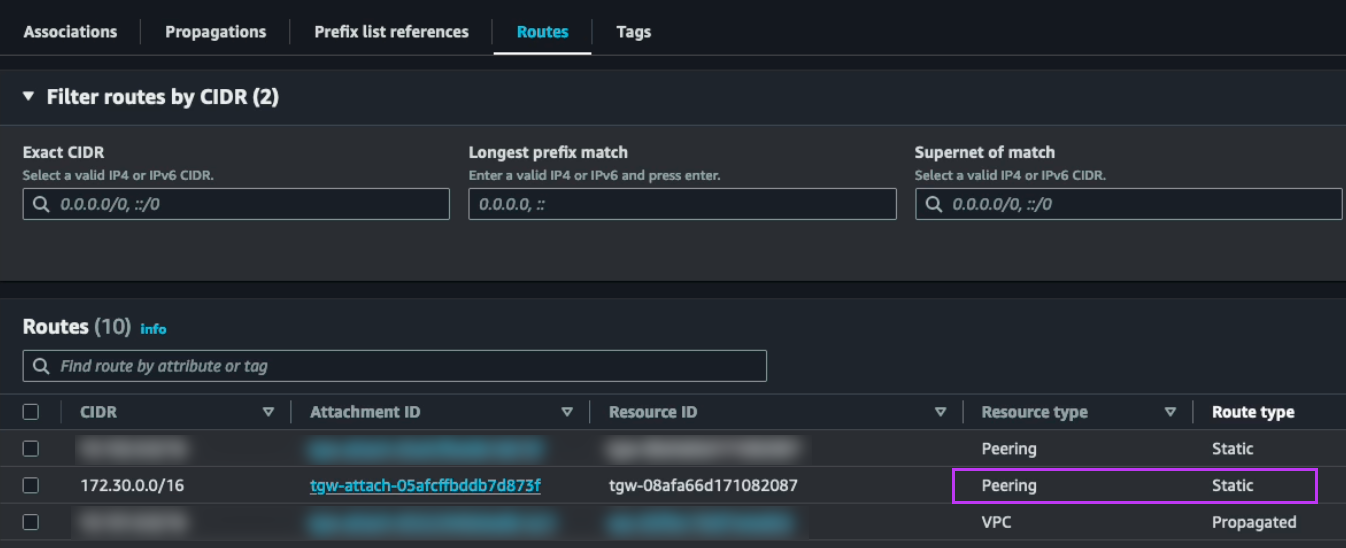
また、東京TGWの静的ルートも更新し、ローカルのNC2 VPCを指すルートを大阪へのピアリング接続に変更します。
結果とまとめ
これらのルーティング変更が適用されることで、オンプレミスのデータセンターからのユーザーは、同じIPアドレスを使用して同じVMにアクセスし続けることが可能になります。この一貫性は、EC2からNC2への移行、および東京リージョンから大阪リージョンへの災害復旧計画に基づいたフェイルオーバー後も維持されます。
このソリューションにより、AWS上で動作していたワークロードがNC2上で動作するようになり、その後もIPアドレスを変更することなく運用を継続できます。これにより、ユーザーにとっての影響を最小限に抑えつつ、DR計画を実現できます。
ぜひこのソリューションを試してみてください。また、この種のソリューションに興味がある場合は、Nutanixの担当者にお問い合わせください。お読みいただきありがとうございました!
リンク
- Terraform / Open Tofu templates used to build the test environment
- PowerShell and Python code used
- Nutanix NC2 page
- Nutanix Move manual